
CI/CD Pipelines are the way of the present. They allow for repeatable, predictable actions & results, which, while boring for real life, is great for your infrastructure needs. In my experience, setting up any pipeline is initially a pain in the butt, what with silently failing steps or then complex, opaque, & often incomprehensible error messages.
The time invested in this process is worth it, though, as once you have it configured properly, you can leave it to its own devices without you having to remember the steps, find the tokens/API keys, or the command flags to get your new code into production. The computer is your best pedantic, reliable friend who does the boring stuff for you without complaining.
There are, as you probably know, ever so many ways to build your pipeline. It appears to be the sexy new product in the tech space: Gitlab, TeamCity, GitHub, BitBucket, Bamboo, Circle Ci, and others. I mean, seriously, the list goes on and on. For a long time, I was just old-school bash scripting my code into production with perfectly good outcomes, but that doesn’t look as cool on my LinkedIn now, does it?
Now is not the time to discuss the benefits of bash over dedicated pipeline solutions or to discuss the differences between all the new tech stacks. Because, let’s face it, they are all quite similar. Whether you’re using a GUI or creating the YAML yourself, you are the queen of how it all goes down, with most giving you all the precision you need to achieve your goals.
Stages to build CI/CD Pipelines
At MergeBase, we have many steps built into our build pipelines, but I often wonder about the order in which they should all be running, whether or not it makes sense to run the scan stage on every push, and whether to scan on a push to a feature branch or just on a push to the main branch. So, let’s look at that now.
In pipeline creation, as in life, I like to fail fast. That is, what’s the most egregious error that I need to stop dead in its tracks? What is the worst type of failure that I can conceive of that would force my pipeline execution to fail? Failing unit tests? Failing end-to-end testing (Cypress, Maven)? Insecure imports in the code (Dependency Check, MergeBase, Mend)? The quality of the code (SonarQube, ReSharper, Codacy)? What is the stage that takes the longest to finish & does it return life or death results (death being the prevention of code going into the main branch)?
Personally, I scan in the first stage. The thinking behind this is that if a component is vulnerable and you need to either update or replace it, you will have to go back to the code, update the component version, and then depending on the new component, you might need to change the code itself. Because of this, it doesn’t make sense to run it after something like SonarQube (a code quality scan). The testing stage should be run after the SCA scan, as it doesn’t matter what the code quality is like if your tests do not pass.
In summation, this is the order in which I like to run my stages: MergeBase scan stage, testing stage, then lastly, the code quality stage. This order, of course, depends on the project & the language in which it is written, but this is usually the way I go, as the stages are ordered according to the importance of their failure in the next stage.
Scanning different languages
Depending on the language you’re scanning, you could theoretically just scan when you change the dependency file instead of every change committed to the entire codebase. So, for example, if you were using GitLab CI/CD, you would add the following to your stage:
rules: - changes: - "\*\*/\*.json" - "\*\*/\*.lock"
This would then restrict the stage to only running when you add or remove packages to your codebase, which in turn changes your dependency file. This sounds like it could be the way to go, except for the fact that vulnerabilities are added or changed quite regularly, so if you went a while without changing your dependencies, your project would be unprotected.
The question then becomes, is skipping the scan on each commit worth saving the time it takes? The answer is yes; because you have a massive codebase or you have many developers committing changes several times a day, then you might want to run the scan stage as a cron job regularly. Keep in mind, though, that you can only do this with certain language codebases.
Python, JavaScript, Ruby, and .NET let you scan with just their dependency file, but Java, PHP, and C need to look through all the files to do a thorough scan. Overall, though, this does not seem worth the perceived time saved.
Reducing the Number of Scans
If you do want to reduce the number of scans you are running each day, you might want to just scan on pushes to the main and leave all pushes to feature branches unscanned. This could improve the updating flow for your dev team and make their daily work quicker.
An example of how to do this in Gitlab would be to add the following to your scan stage:
only:
-main
In terms of actually adding a MergeBase scanning stage, this is all it takes:
wegt --header="X-Authorization:$MB_TOKEN" https://{your-dashboard-url}/api/update/clt/mergebase.jar
java -jar mergebase.jar --name=yourAppName . --all`
In the first line, we are getting the jar file from your MergeBase account. To do this, you will need to get your MB API token from your MB dashboard. This is found on the Settings page, whose button you will find in the bottom left corner of the main page.
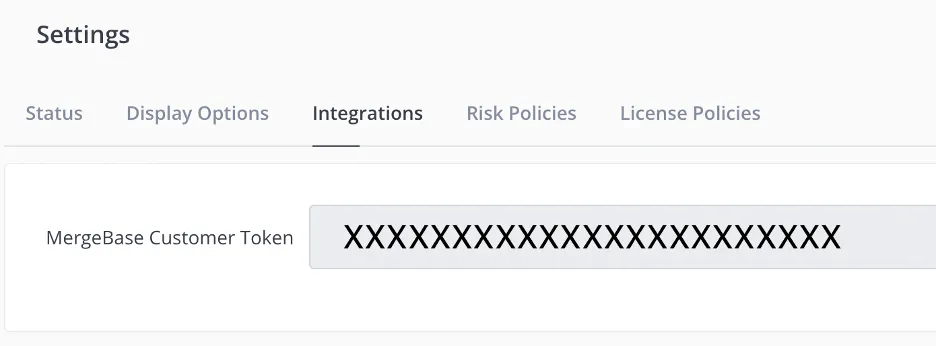
Copy this token into a “hidden” var to not have it in your git repo. Following are screenshots showing how to save it in Gitlab as MB_TOKEN and so use it in our pipeline as the variable $MB_TOKEN.
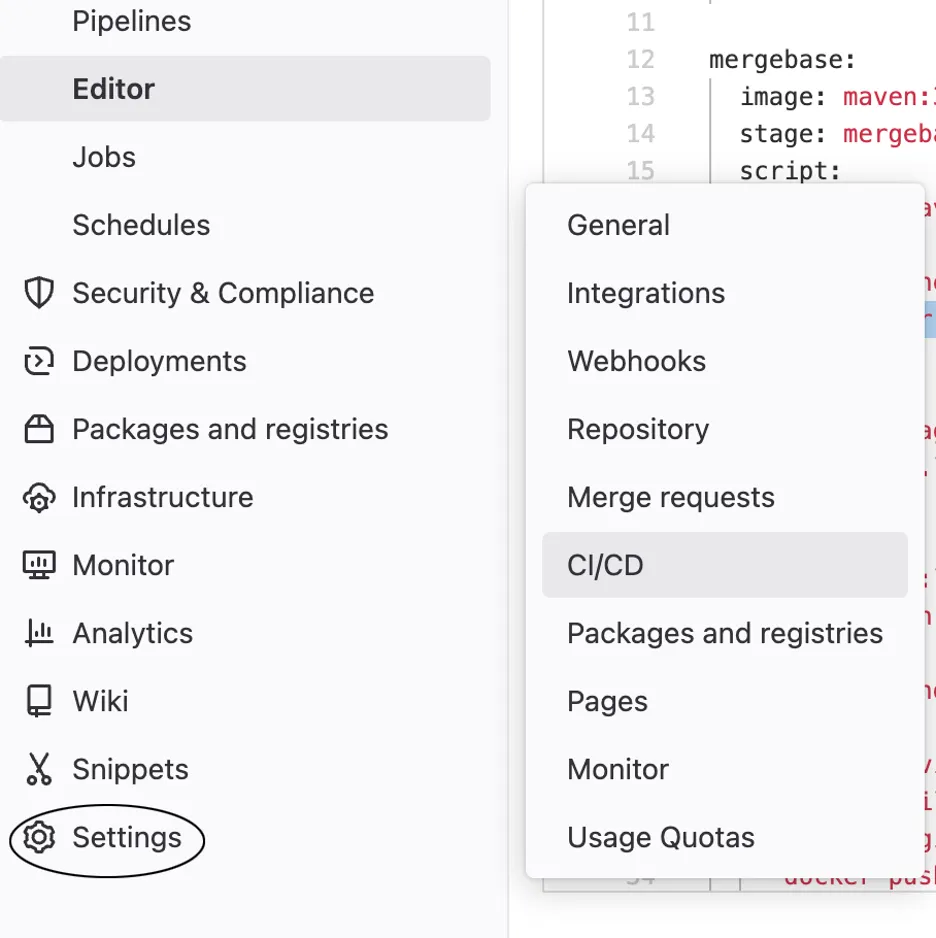

Now that we have our MB token saved as a variable, we can use it in our & add the returned path to your wget command.
Then the only thing to figure out is how to figure out the jar url. This can be done by combining the url of your dashboard + the following string:/api/update/clt/mergebase.jar
https://{your-dashboard-url}/api/update/clt/mergebase.jar
Next, you run the same command as you would locally to invoke your MB scan. I would definitely recommend a direct copy/paste from your local terminal so that you receive the expected results without too much editing of your pipeline YAML.
And there you have it! A MergeBase scan is now included in your pipeline.
MergeBase CI/CD Integrations
Here is a list of links with specific instructions according to specific systems.
All of these can also be found on our integration page.
As you can see, it is incredibly easy to integrate a MergeBase stage into any of your existing pipelines.
But before you go, how about starting scanning your apps with MergeBase?
